Virtual Listener Panel™: AI prediction of sound quality
The Virtual Listener Panel™ (VLP) is your cloud-based solution powered by advanced AI, trained on extensive datasets collected through SenseLab’s expert listener panels.
Perceptual characterisation of your audio product 24/7
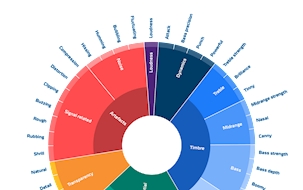
Specifically designed for audio professionals, the Virtual Listener Panel leverages SenseLab's trusted Sound Wheel attributes, enabling precise, attribute-specific characterization of your audio products around the clock.
Streamlined, data-driven audio optimization
With VLP, optimizing your audio attributes has never been easier or more insightful. Simply upload your recordings or simulations to instantly receive detailed perceptual analyses of key audio attributes. Explore how different tuning decisions influence specific sound characteristics, quickly and clearly seeing how close your current tuning is to a reference or benchmark product.
Why Choose VLP?
- Objective, reproducible perceptual evaluations based on expert listener model
- Fast, reliable attribute insights - scalable to your project's complexity
- Immediate benchmarking against previous tunings or competitive standards
- Perfecting your product’s audio performance
Take your audio product's perceptual characterization to the next level - efficiently and effortlessly.
I’ve tested the Virtual Listener Panel several times and was genuinely impressed with the overall results. The interface is intuitive, making it easy to import, compare, and present audio samples - even to non-engineers. It has great potential, especially for comparing similar cartridges under standardized conditions. The tool proves valuable for refining product communication and internal decision-making. Our team sees strong potential in using VLP to enhance the way we present and differentiate our products.Dovydas Vaitkus, Electro-acoustic Engineer / Ortofon
Contact SenseLab
Get started today
Sign up for free to start analysing your audio files. Once you have registered, you can upgrade to a plan that fits your needs.Optimising the sound of your product has never been easier:

1. Add your audio files
Add music recordings or software tunings of different products
2. Explore your recordings
Listen to your recordings and explore them in depth with customizable spectrogram views
3. Loudness-align your files
You can play and export your files at your preferred loudness-aligned level
4. Run the analysis
Within seconds or minutes and you can interact with the results and export the results
5. Customise your experience
VLP allows you to add elements, customize and interact with them, and save layouts as you prefer
6. Save the results
You can save the progress in workspaces at any time - to a local file or in the cloudUnderstand VLP and find your plan
Understand how VLP works and find a plan that matches your requirements
Navigate through our products and services
Related content

Explore SenseLab's sound quality laboratories
/Facility

Meet SenseLab's expert team
/Page
Leading team in acoustics, sound quality and perceptual evaluation, guiding in audio solutions.

Partnership on product sound quality tests
/News
FORCE Technology establishes partnership with Sound Hub Denmark to support sound innovation.

Bluetooth SIG
/Case
Impartiality makes all the difference to the standardisation organisation Bluetooth SIG.

SenseLab: Experts in high-tech audio testing
Trusted partner for high-tech audio testing and listening tests helps you validate and enhance your product claims.